Wir geben etwas mehr über die Verdienste, die wir heute mit "künstlicher Intelligenz" meinen. Dieser Begriff ist eng mit neuronalen Netzen verbunden, nicht so viel aus funktionellen Gründen wie aus topologischen Gründen. Wenn tatsächlich die Definition von künstlicher Intelligenz rein funktionell ist, d.h. sie sagt, was sie eine Maschine als intelligent betrachten muss oder sollte, wird das neuronale Netz als menschliches Gehirn strukturiert und erinnert daher topologisch an die Intelligenz selbst.
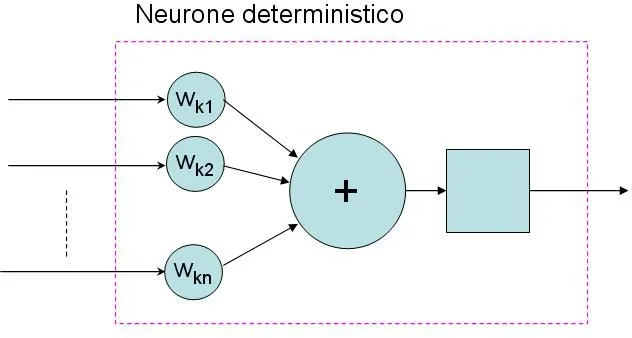
im menschlichen Gehirn sind Zellen, die zu den Funktionen des Denkens bestimmt sind, Neuronen. ein Neuron besteht hauptsächlich aus drei Elementen, einem "Dendriten", d.h. dem Eingang des Neurons, einem "Aston", d.h. dem Ausgang und dem Zellkörper. Letztere nimmt die ankommenden Informationen unter Form von elektrischen Spannungen auf, macht sie zu einer gewogenen Summe, und wenn der resultierende Wert eine bestimmte Schwelle überschreitet, aktiviert dann seine Leistung. der Ausgang des Neurons geht, um den Eingang für andere Neuronen zu bilden, wodurch ein echtes Netzwerk gebildet wird.
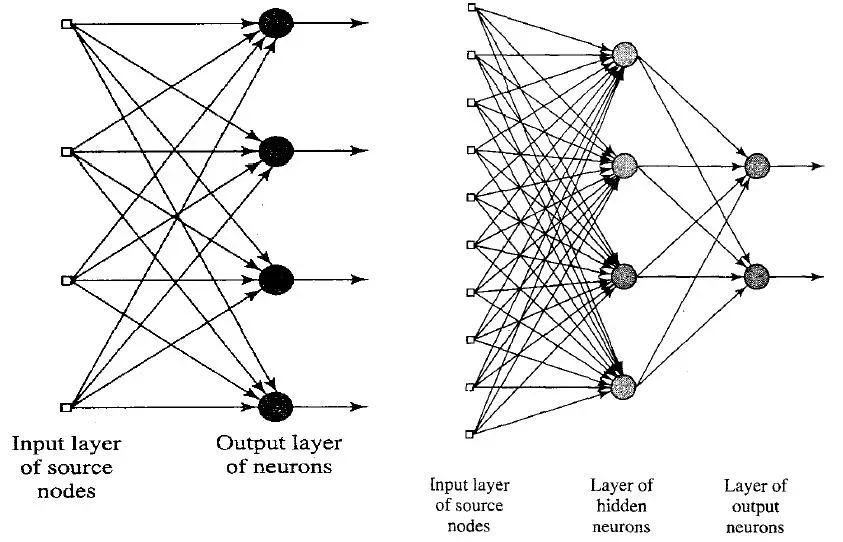
Viele Gelehrte sind sich einig, dass die Kraft des menschlichen Gehirns (aber auch des Tieres) ausschließlich in seiner Topologie besteht, so sind Neuronen miteinander verbunden. Es ist daher natürlich zu denken, dass durch das Kopieren dieser Struktur in ein künstliches System die Nachbildung von Intelligenz möglich sein sollte. Es ist nicht so, oder zumindest, es war nicht bis heute. in diesem Beitrag:
http://www.cad3d.it/forum1/showpost.php?p=274783&postcount=71 Ich habe etwas erwartet.
In Wirklichkeit ist ein bemerkenswerter Vorteil der "Hardware"-Strukturen, wo das neuronale Netzwerk physisch ist, wie im menschlichen Gehirn, der parallele Prozess, der sich entwickelt. das menschliche Gehirn ist extrem langsamer als ein pc, aber viele Operationen (wie Gesichtserkennung, ocr Lesung, etc.) werden mit vergleichbaren Geschwindigkeiten durchgeführt. Warum? einfach, weil in pcs programmierte neuronale Netze tatsächlich sequentiell sind. Obwohl Topologie ähnlich sein kann, ist cpu ein und zählt zu einem Zeitpunkt, obwohl bei der Auftragsgeschwindigkeit 3x10^9 Operationen pro Sekunde. ein menschliches Neuron kann etwa 200 Schalter pro Sekunde machen und seine Ausgänge bewegen sich auf etwa 100m/s, aber das menschliche Gehirn hat etwa 10^11 Neuronen mit einer Schmutzzahl von Synapsen (Verbindungen). Daher kann bei allen Operationen, bei denen die Topologie des humanen neuronalen Netzes bis zum Maximum ausgenutzt wird, die Verarbeitungsgeschwindigkeit mit derjenigen eines pc verglichen werden, bei der Erstellung von arithmetischen Konten statt ist der pc offensichtlich unschlagbar.
das Konzept von Geschwindigkeit und Parallelität gut zu verstehen, machen wir ein Beispiel für ein sehr einfaches Problem. auf dem Tisch gibt es 9 gleiche Bleistifte und eine kürzer als die anderen. fordert, den kürzesten Bleistift zu identifizieren. a pc führt den folgenden Algorithmus aus:
9 mal laufen:
Ist der Bleistift kürzer als der Bleistift 'i+1'?
Ja -> Ausgang = Bleistift 'i '
Nein Ausgang = Bleistift 'i+1 '
am Ende des Zyklus ist der Ausgang der kürzeste Bleistift. das menschliche Gehirn gibt stattdessen einen Blick auf den Tisch und nimmt direkt, mit einer einzigen Operation, die kürzere Matte. mit 10 Bleistiften ist der pc schneller, aber mit 100 oder 1000 oder 10^6 oder 10^9 Bleistiften? der pc muss eine zunehmende Anzahl von Konten machen, während die Anzahl der Operationen (Parallelen) notwendig für das menschliche Gehirn immer und nur eins sein wird.
Es gibt jedoch sogenannte "Neurocomputer", d.h. Computer, die die Struktur eines neuronalen Netzes durch Hardware replizieren.
") zu einem First-Person-Shooter (unter dem besten "Kall der Pflicht") Ihre Gegner würden nicht in der Lage sein, durch automatische Schüsse geschlachtet zu werden, sondern würde Schutz hinter Wänden suchen, Kisten, Naturschutz, etc.
zu einem First-Person-Shooter (unter dem besten "Kall der Pflicht") Ihre Gegner würden nicht in der Lage sein, durch automatische Schüsse geschlachtet zu werden, sondern würde Schutz hinter Wänden suchen, Kisten, Naturschutz, etc.